424. Longest Repeating Character Replacement 替换后的最长重复字符
- 作者: 负雪明烛
- id: fuxuemingzhu
- 公众号:负雪明烛
- 本文关键词:LeetCode,力扣,算法,算法题,字符串,双指针,刷题群
@TOC
题目地址:https://leetcode.com/problems/longest-repeating-character-replacement/description/
题目描述
Given a string that consists of only uppercase English letters, you can replace any letter in the string with another letter at most k times. Find the length of a longest substring containing all repeating letters you can get after performing the above operations.
Note: Both the string's length and k will not exceed 104.
Example 1:
Input:
s = "ABAB", k = 2
Output:
4
Explanation:
Replace the two 'A's with two 'B's or vice versa.
Example 2:
Input:
s = "AABABBA", k = 1
Output:
4
Explanation:
Replace the one 'A' in the middle with 'B' and form "AABBBBA".
The substring "BBBB" has the longest repeating letters, which is 4.
题目大意
求一个字符串修改k个字符后,能够成的最长的相同字符组成的连续子序列。
解题方法
双指针
首先需要区分两个概念:子串(子数组) 和 子序列。这两个名词经常在题目中出现,非常有必要加以区分。子串sub-string(子数组 sub-array)是连续的,而子序列 subsequence 可以不连续。
我读完今天这个题目之后,脑子里把题目转成了另外一个表达方式:求字符串中一个最长的区间,该区间内的出现次数较少的字符的个数不超过 k。
上面的表达方式跟题目是等价的,抽象成这种表达方式的好处是让我们知道这是一个区间题,求子区间经常使用的方法就是双指针。
《挑战程序设计竞赛》这本书中把双指针叫做「虫取法」,我觉得非常生动形象。因为双指针移动的过程和虫子爬动的过程非常像:前脚不动,把后脚移动过来;后脚不动,把前脚向前移动。
我分享一个双指针的模板,能解决大多数的双指针问题:
def findSubstring(s):
N = len(s) # 数组/字符串长度
left, right = 0, 0 # 双指针,表示当前遍历的区间[left, right],闭区间
counter = collections.Counter() # 用于统计 子数组/子区间 是否有效
res = 0 # 保存最大的满足题目要求的 子数组/子串 长度
while right < N: # 当右边的指针没有搜索到 数组/字符串 的结尾
counter[s[right]] += 1 # 增加当前右边指针的数字/字符的计数
while 区间[left, right]不符合题意:# 此时需要一直移动左指针,直至找到一个符合题意的区间
counter[s[left]] -= 1 # 移动左指针前需要从counter中减少left位置字符的计数
left += 1 # 真正的移动左指针,注意不能跟上面一行代码写反
# 到 while 结束时,我们找到了一个符合题意要求的 子数组/子串
res = max(res, right - left + 1) # 需要更新结果
right += 1 # 移动右指针,去探索新的区间
return res
简单介绍上面的模板,模板的思想是:以右指针作为驱动,拖着左指针向前走。右指针每次只移动一步,而左指针在内部 while 循环中每次可能移动多步。右指针是主动前移,探索未知的新区域;左指针是被迫移动,负责寻找满足题意的区间。
模板的整体思想是:
- 定义两个指针
left和right分别指向区间的开头和结尾,注意是闭区间;定义counter用来统计该区间内的各个字符出现次数; - 第一重
while循环是为了判断right指针的位置是否超出了数组边界;当right每次到了新位置,需要增加right指针的计数; - 第二重
while循环是让left指针向右移动到[left, right]区间符合题意的位置;当left每次移动到了新位置,需要减少left指针的计数; - 在第二重
while循环之后,成功找到了一个符合题意的[left, right]区间,题目要求最大的区间长度,因此更新res为max(res, 当前区间的长度)。 right指针每次向右移动一步,开始探索新的区间。
模板中为什么不把 counter 放在 while 循环内部呢?因为如果放在 while 内部每次新建一个 counter 变量,统计区间的字符出现次数的时间复杂度是 O(N) ;放在 while 外部,每次增加 right 指向的字符的计数、减少 left 指向的字符的计数的是时间复杂度是 O(1) 。这也是常见的统计区间问题时的技巧。类似的,如果我们要求一个区间的和的话,也可以用类似的思想去做。
代码
今天的代码可以直接套用上面的双指针模板,内层的 while 循环中的判断条件该区间内出现次数较少的字符的出现次数是否大于 k 。如果大于 k 的话,说明该区间不符合题意,需要移动 left 指针直至符合题意为止。
如果理解了上面的双指针模板之后,我做了动图帮助理解。
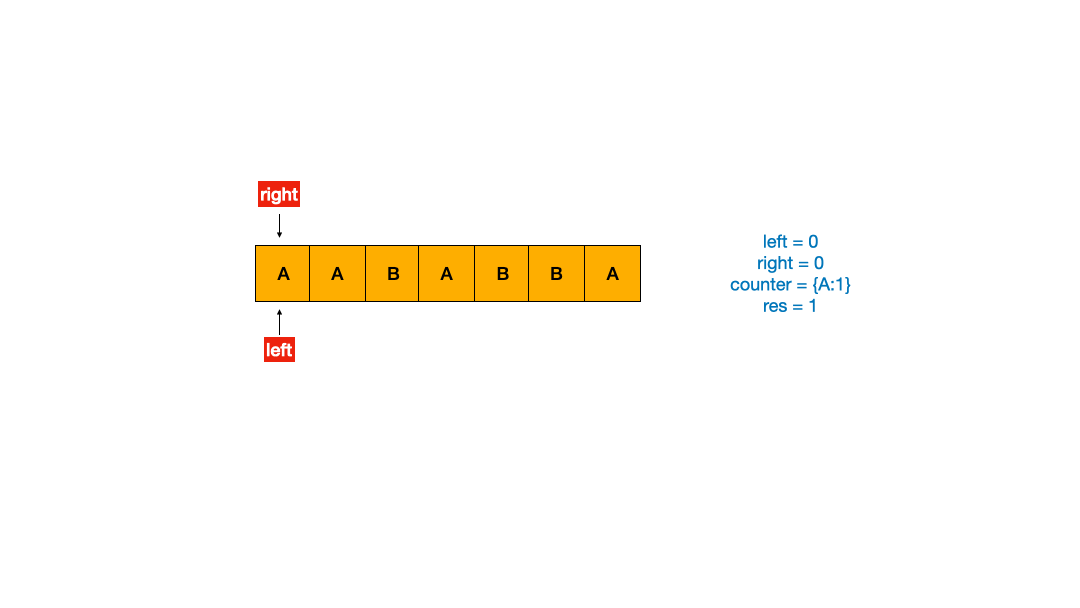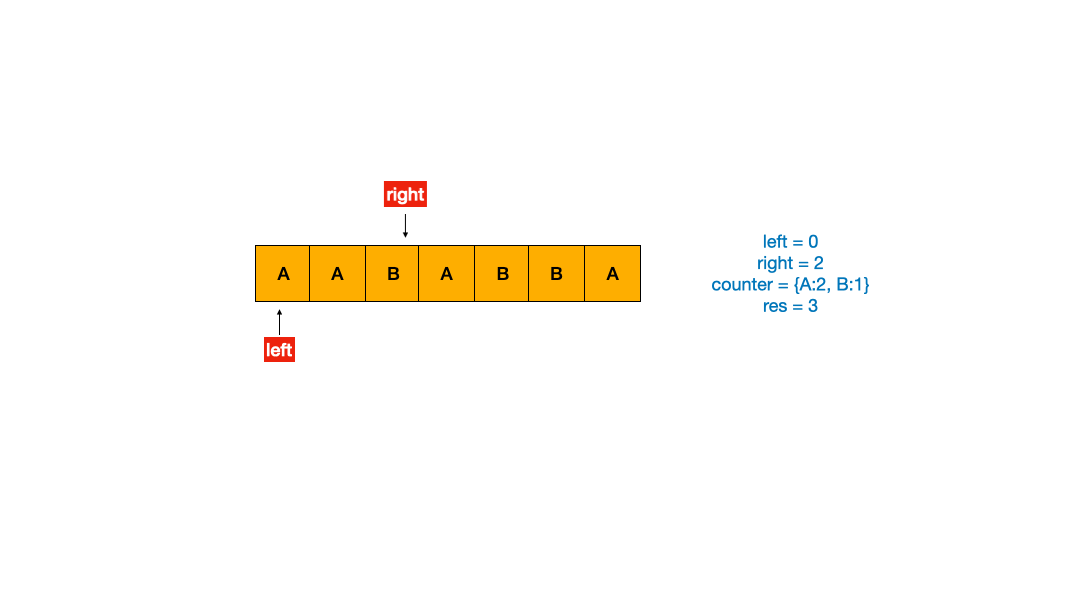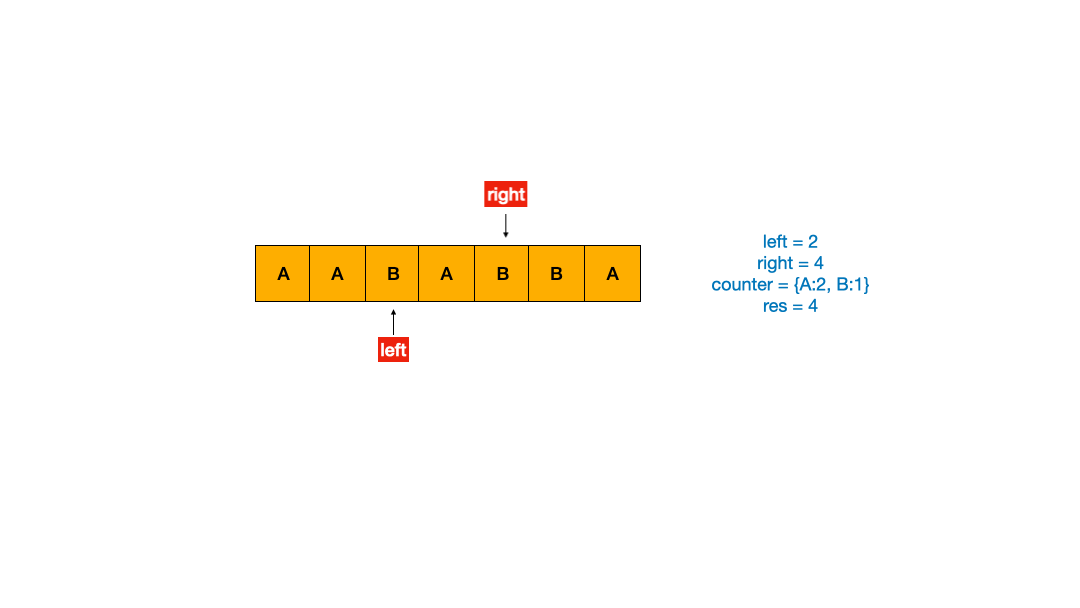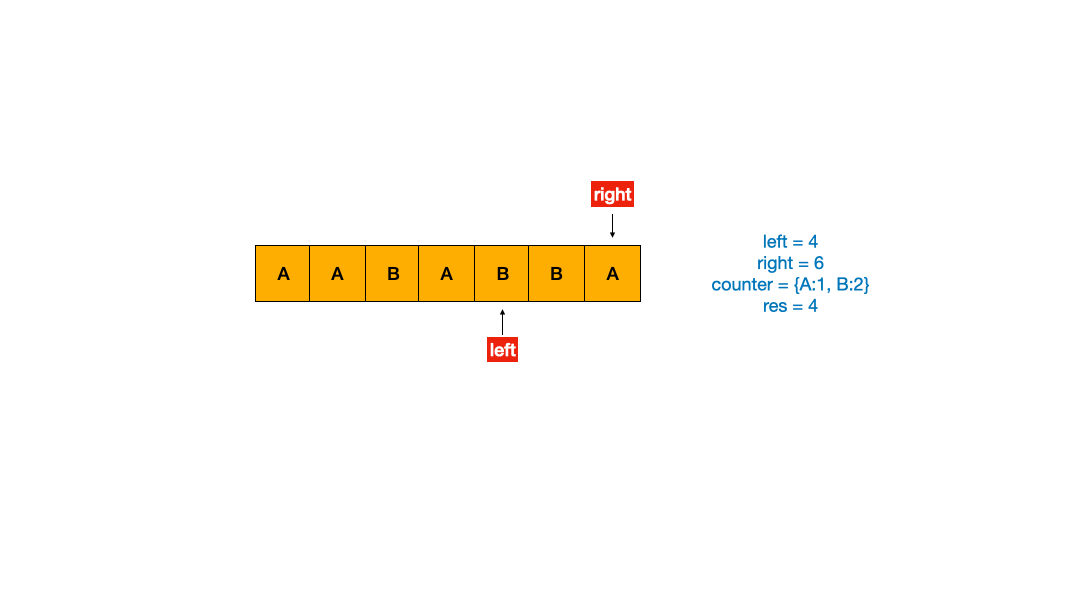
使用 Python2 写的代码如下。
class Solution(object):
def characterReplacement(self, s, k):
"""
:type s: str
:type k: int
:rtype: int
"""
N = len(s)
left, right = 0, 0 # [left, right] 都包含
counter = collections.Counter()
res = 0
while right < N:
counter[s[right]] += 1
while right - left + 1 - counter.most_common(1)[0][1] > k:
counter[s[left]] -= 1
left += 1
res = max(res, right - left + 1)
right += 1
return res
欢迎加入组织
算法每日一题是个互相帮助、互相监督的力扣打卡网站,其地址是 https://www.ojeveryday.com/
想加入千人刷题群的朋友,可以复制上面的链接到浏览器,然后在左侧点击“加入组织”,提交力扣个人主页,即可进入刷题群。期待你早日加入。
欢迎关注我的公众号:每日算法题

日期
2018 年 3 月 12 日 2021 年 2 月 2 日 —— 现在题解的这个动图是我做的第一个动图